Deep Learning 101
Deep Learning 101, Taiwan’s pioneering and highest deep learning meetup, launched on 2016/11/11 @ 83F, Taipei 101
AI是一條孤獨且充滿惶恐及未知的旅程,花俏絢麗的收費課程或活動絕非通往成功的捷徑。
衷心感謝當時來自不同單位的AI同好參與者實名分享的寶貴經驗;如欲移除資訊還請告知。
由 TonTon Huang Ph.D. 發起,及其當時任職公司(台灣雪豹科技)無償贊助場地及茶水點心。


去 YouTube 訂閱 | Facebook | 回 GitHub Pages | 到 GitHub 點星 | 網站 | 到 Hugging Face Space 按愛心
| 大語言模型 | 語音處理 | 自然語言處理 | 電腦視覺 |
|---|---|---|---|
| Large Language Model | Speech Processing | Natural Language Processing, NLP | Computer Vision |
避開 AI Agents 與 Agentic AI 開發陷阱
那些實戰踩過的坑、常見問題、挑戰與解決方案
前言 Introduction
AI 技術迅速發展,各種開源與商用工具層出不窮。然而,許多開發者在實戰中踩過不少坑——不論是工具穩定性、安裝複雜度,還是搜索準確率、引用錯誤等問題,都成為推動 AI 代理 (AI Agents,以下簡稱「AI Agents」) 與 代理式人工智慧 (Agentic AI,以下簡稱「Agentic AI」) 真正落地的障礙。
本文將探討多種AI Agents 與 Agentic AI 工具 (含 MCP) 的應用、經驗與挑戰,分享避坑指南與推薦,更針對可能會碰上的資安問題,提出解決方向,希望更高效、正確地建構 AI Agents 與 Agentic AI 系統的落地。
從定義之爭到「特性程度」:吳恩達對「Agent」與「Agentic」的務實觀點
在探討 AI Agents 與 Agentic AI 的細節之前,值得借鑒吳恩達與 LangChain CEO Harrison Chase 對話中的一個核心觀點。吳恩達認為,與其糾結一個系統「是不是」Agent,不如接受「智能體特性」(agenticness)的程度差異。他回憶道,過去許多人熱衷於爭論某個系統「是不是真正的 agent」、「是否足夠自主」,但他認為這種爭論意義不大。他提倡使用「智能體化系統」(agentic systems)來描述具有不同自主程度的應用,無論是少量自主性還是大量自主性,都無需浪費時間爭論其是否「真正」是一個 agent。這一提法有助於減少不必要的爭論,讓大家更專註於建構本身,為我們理解和應用後續概念提供了務實的基礎。
人工智慧領域正經歷典範轉移,從被動的生成式模型邁向更具自主性、能執行複雜任務的 AI Agents 和 Agentic AI。這股趨勢自 2022 年底 ChatGPT 問世後,在 Google 全球搜尋趨勢上呈現顯著上升。傳統搜尋引擎主要作為中介,引導使用者至原始內容來源,而新興的生成式搜尋工具則自行解析並重新包裝資訊,這可能導致原內容來源的流量減少。
更甚者,這些工具在資訊品質和引用方面存在嚴重問題:多數 AI Agents 無法準確搜尋並引用文章來源,經常「自信地提供錯誤答案」,即使是付費服務也難以避免內容錯誤。它們可能忽略 `robots.txt` 協議抓取禁止內容,引用錯誤版本或聚合來源,甚至提供無效或偽造的連結,難以追溯真實出處。 這促使我們需要更深入地檢視這些新興 AI 系統的內部運作、實際應用與潛在風險。
參考文獻 (Key References)
AI Search Has A Citation Problem, (Columbia Journalism Review, May 2025):生成式 AI 在知識引用上的嚴重信任斷裂問題。
AI Agents vs. Agentic AI, (Cornell University, May 2025):AI Agents 與 Agentic AI 概念上的差異與連結。
OWASP Agentic AI – Threats and Mitigations:系統性揭露 Agentic AI 面臨的新型威脅,並提供實務對策。
Andrew Ng: State of AI Agents | LangChain Interrupt:一場 LangChain CEO Harrison Chase與Andrew Ng的爐邊對話。
AI Agents vs Agentic AI:趨勢觀察 Global and Taiwan Trends
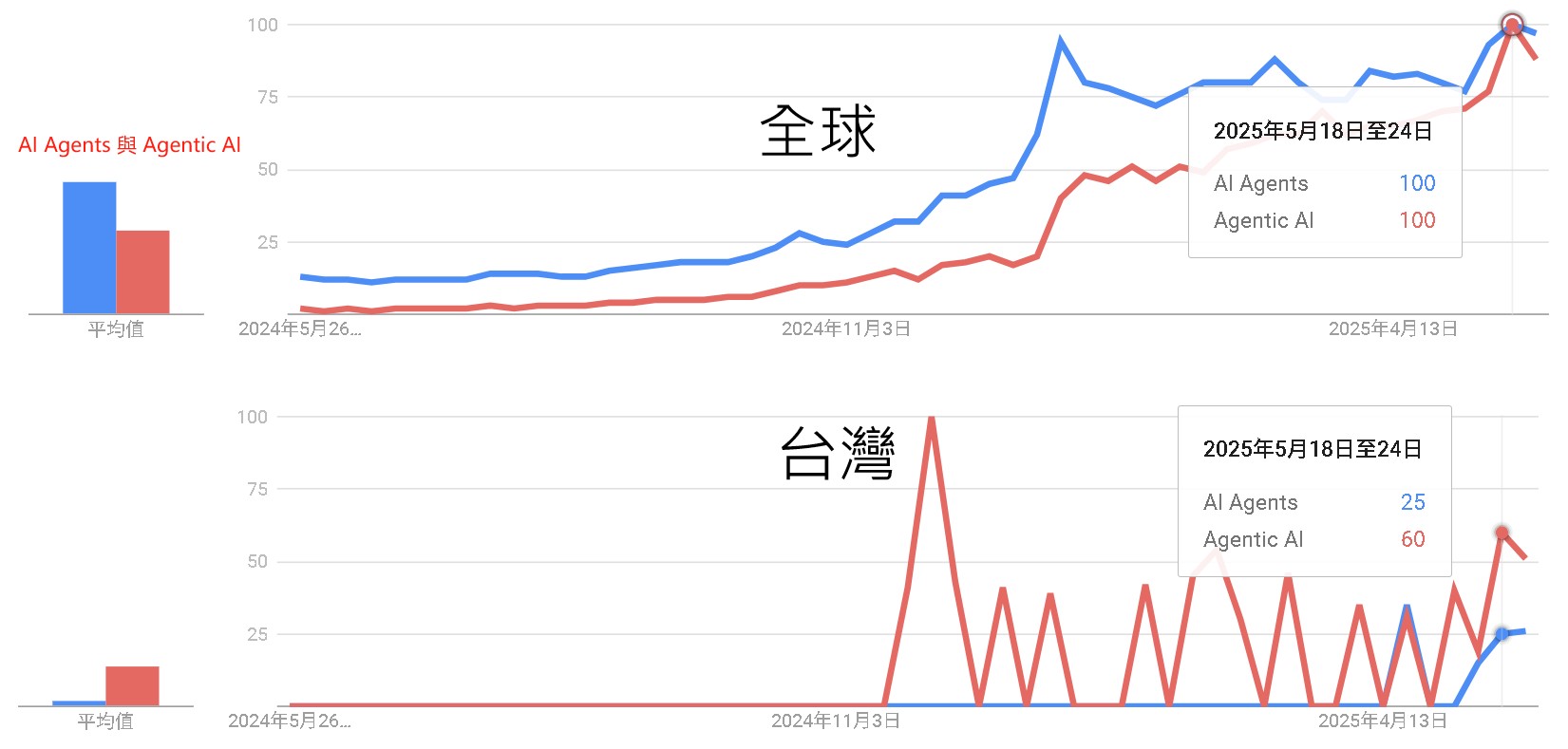
關於 AI 代理 (AI Agents) 與 代理式人工智慧 (Agentic AI),全球趨勢呈現了概念從基礎到進階的自然演進與普及過程;而台灣的趨勢則更多地受到語言習慣、特定事件和小眾專業社群對前沿英文術語直接採用的影響,導致與全球趨勢有顯著差異。
全球趨勢推斷原因:
- 「AI Agents」作為基礎且廣泛的術語,較早獲得全球市場的持續關注與穩定成長。
- 隨著技術發展與討論深化,「Agentic AI」這一更特定、進階的概念隨後興起,反映了專業度的提升。
- 兩者熱度最終趨於一致,顯示市場對 AI Agents 的理解從普遍認知逐漸演進至更精確的專業細分。
台灣趨勢推斷原因:
- 台灣市場因使用者普遍傾向以中文搜尋,導致「AI Agents」此英文術語的整體關注度相對較低。
- 「Agentic AI」的熱度則呈現由特定事件或專業社群驅動的尖峰,這些群體可能直接採用此外來的前沿術語進行討論。
- 此現象反映了資訊傳播的集中性,以及對特定新興技術點的跳躍式關注,而非如全球般呈現漸進式的術語普及。
什麼是 AI 代理 (AI Agents)?它們與生成式 AI 有何不同? AI Agents vs. Generative AI
從資訊工程的角度來看,AI Agents 是一種設計用在特定數位環境中執行目標導向任務的自主軟體實體。它們的核心能力在於能夠感知環境、對上下文資訊進行推理,並採取行動以達成預設目標。與傳統的自動化腳本不同,AI Agents 具備一定程度的反應性和適應性。
AI Agents 的出現是建立在生成式人工智慧(亦稱生成式AI 或 Generative AI,以下簡稱 GenAI)的基礎之上。GenAI 模型(如大型語言模型 LLMs 和大型圖像模型 LIMs)主要透過接收提示來生成新的內容(文本、圖像、程式碼等),它們是「輸入驅動」的,缺乏內部狀態、持久記憶或目標追蹤機制。它們的設計沒有內建的回饋迴圈、狀態管理或多步驟規劃。可以說,GenAI 是 AI Agents 的前身。
AI Agents 則在 LLMs 的語言處理基礎上,引入了額外的基礎設施,例如記憶緩衝區、工具呼叫 API、推理鏈和規劃例程。這彌補了被動響應生成與主動任務完成之間的差距。LLMs 成為現代 AI Agents 的核心推理引擎,賦予代理理解自然語言、規劃多步驟解決方案和生成自然響應的能力。LIMs 則將能力擴展到視覺領域。
AI Agents 的核心特徵 (Core Features of AI Agents)
- 自主性(Autonomy): 在部署後能夠以最少甚至無需人為干預的方式運作。
- 任務特定性(Task-Specificity): 通常被設計用於狹窄、定義明確的任務。
- 反應性(Reactivity): 對環境或使用者輸入做出回應。
- 工具整合(Tool Integration): 能夠呼叫外部工具和 API 來完成任務。
例如,ChatGPT 結合 Web Search API 獲取即時資訊就是一個工具增強型 AI Agents 的例子。
什麼是代理式人工智慧 (Agentic AI)?它如何超越單一 AI Agents? Agentic AI: Beyond Single Agents
Agentic AI 代表了 AI 系統架構的一種「典範轉移」。它不再是單一實體的 AI Agents,而是由多個專門的 Agents組成,這些Agents協同工作以實現更複雜、高層次的目標。這是一種更高級別的自主系統,強調多代理之間的協作、動態適應和協調。
Agentic AI 的關鍵推動因素 (Key Drivers of Agentic AI)
- 目標分解(Goal Decomposition): 將複雜的使用者指定目標自動解析並分解為更小、可管理的子任務。
- 多步驟推理和規劃(Multi-step Reasoning and Planning): 促進子任務的動態排序,以適應環境變化或部分任務失敗。
- 代理間通訊(Inter-agent Communication): 代理之間透過分散式通訊通道(如非同步訊息佇列)交換資訊,實現協調而無需持續的中心化監督。
- 反思性推理和記憶系統(Reflective Reasoning and Memory Systems): 允許代理跨多次互動保留上下文,評估過去的決策並迭代改進策略。
Agentic AI 系統架構增強 (Architectural Enhancements)
Agentic AI 架構在 AI Agents 的基礎上進行了增強,以支援分散式智慧和 Agents 間通訊。關鍵增強包括:
- 專門代理集合(Ensemble of Specialized Agents): 系統由多個具有特定功能的代理組成(例如,規劃代理、檢索代理、總結代理)。
- 高級推理和規劃(Advanced Reasoning and Planning): 嵌入遞歸推理能力,使用如 ReAct、Chain-of-Thought (CoT) 和 Tree of Thoughts 等框架。
- 持久記憶架構(Persistent Memory Architectures): 整合記憶子系統以跨任務週期或代理會話保留知識(情節記憶、語義記憶、向量記憶)。
- 協調層 / 元代理(Orchestration Layers / Meta-Agents): 引入協調器或元代理來管理和協調子代理的活動、管理依賴性、分配角色和解決衝突。
Agentic AI 展現出更高層次的自主性,能夠管理需要協調的複雜、多步驟任務。它們的應用領域更廣,從研究自動化、機器人協調到醫療決策支援和智慧家庭生態系統。例如,在智慧家庭系統中,Agentic AI 可以協調天氣預報、日程安排、能源定價最佳化和安全監控等多個代理,以實現整體優化目標。
AI Agents 與 Agentic AI 的實際應用與工具生態 Practical Applications & Tool Ecosystem
AI Agents 與 Agentic AI 的開發與部署仍處於快速演進期。許多開源與商用工具應運而生,旨在降低開發門檻並提供豐富的功能。
線性工作流的潛力:吳恩達眼中的「低垂果實」
吳恩達在與 Harrison Chase 的對話中指出,儘管他的團隊會使用 LangGraph 這類工具處理具有複雜流程的高難度問題,但他同時看到了大量商業機會潛藏在相對線性的工作流程中。「許多商業場景中,現有的流程是這樣的:員工查看網站表單,進行網站搜索,檢查其他數據庫以確認合規性或客戶風險,然後複製粘貼信息,可能再進行一次網頁搜索,最後粘貼到另一個表單中。」吳恩達描述道。他認為,這些商業流程中存在大量相當線性的工作流,或只是偶爾帶有分支的線性流程。將現有業務流程有效地轉化為智能體工作流是一大挑戰,包含如何確定任務分解的粒度、原型效果不佳時如何改進等,這種審視、分解、評估的整體技能目前仍然「非常稀缺」。
AI Agent 開發的「樂高」心法:組合與迭代
談及智能體構建者應掌握的技能,吳恩達提出了「樂高積木」的比喻。他認為,過去幾年 AI 公司創造了大量優秀的 AI 工具,如 LangGraph 等編排工具,以及 RAG(檢索增強生成)、聊天機器人構建方法、多種記憶系統、評估(evals)和護欄(guardrails)等。成功的智能體構建者應像樂高積木的組裝者,能夠快速組合這些專業工具,而不是一切從零開始。掌握並熟練運用這些「積木塊」,能夠極大提升開發效率和決策速度。吳恩達也提到,隨著 LLM 上下文窗口擴大,一些最佳實踐(如 RAG 的調校)也在演變,RAG 依然重要,但其超參數調整變得更容易。
被低估的機遇:評估、語音與全民程式設計
吳恩達點名了幾個他認為被低估或應用不足的關鍵領域:
- Evals(評估系統): 儘管人們常談論評估,但許多團隊在項目中引入系統性評估的速度遠慢於理想狀態,過於依賴人工評估。他建議評估可以從簡單開始,逐步迭代改進,以有效補充人工評估並針對特定回歸問題進行檢查。
- 語音應用 (Voice Stack): 吳恩達認為語音應用被「嚴重低估」,因其能降低使用者門檻,「用戶只需開口說話」。他指出語音應用對延遲 (latency) 要求極高(通常需 1 秒內回應),並分享了如「預錄製插入語」(如「哦,有意思」)或在客服場景播放呼叫中心背景噪音以掩蓋延遲、提升容忍度的技巧。
- AI 輔助程式設計與「人人都應學習程式設計」: 吳恩達觀察到,使用 AI 輔助程式設計的開發者效率遠高於不使用者。他堅信 AI 輔助程式設計將創造更多而非更少開發者,如同歷史上程式設計工具的進步一樣。他甚至透露,在 AI Fund,包括前台、CFO 和法務總顧問在內的每個人都會程式設計,這能讓他們更好地告訴計算機自己想做什麼,從而在各自崗位上實現顯著的生產力提升。對於近期流行的「Vibe Coding」(氛圍編程),吳恩達認為名稱具誤導性,讓人以為僅憑感覺編程,但實則是一項深度智力活動;AI 輔助編程使得更多人能夠編程,未來最重要的技能之一就是「準確告訴電腦你想要什麼」。
實測與經驗分享
以下為目前較知名的可能主流框架,各有其側重與特性:
-
🌐 Suna (Manus 倒過來寫),2025-04:[3週時間,就打造出Manus開源平替!貢獻原始碼,免費用]
- GitHub:https://github.com/kortix-ai/suna
- 特點: 支援任務自動化、網頁瀏覽、文件處理、API 整合等。
- 案例回放:B2C 人工智慧市場研究
- 功能: 自動化搜尋、內容提取、結構化摘要。
- 體驗: 與主流 Agent 操作一致,界面直觀。
- 優勢: 高自由度,可進行多種定制任務。
-
🧠 OpenManus,2025-03:[一文讀懂:OpenManus]
- GitHub:https://openmanus.github.io
- 背景: MetaGPT 團隊 (DeepWisdom) 於 Manus 發布後僅用 3 小時復刻。
- 特點: 開源、可擴展,屬於輕量級多智能體框架。適合有 Python 基礎的使用者快速上手。
-
🔧 DeepSite,2025-04:[基於DeepSeek的網頁開發智能體]
- HuggingFace:https://huggingface.co/spaces/enzostvs/deepsite
- 案例:🧱 自然語言建站應用:DeepSite
- 特點: 無需寫程式,即可透過自然語言描述生成網站。支援電商、部落格、遊戲等類型網站。提供即時預覽、SEO 優化、快速部署。
-
🧠 Skywork Super Agents,2025-05:[AI版Office全網首測,鍵盤滑鼠徹底退休!打工人沸騰]
- 網址:https://skywork.ai/
- 案例:📊 AI 代理與 Agentic AI 概論 (Skywork-PPT)
- 特點: 基於 AI Agent 架構與 deep research 技術,能一站式生成文檔、PPT、表格、網頁、播客和音視頻等多模態內容。
- 功能: 支援多模態創意任務,如圖片、海報、音樂、MV、宣傳片、有聲讀物、繪本等內容的生成。
- 體驗: 界面直觀,操作簡便,支持移動端與 PC 端的無縫切換,並可搭建私人知識庫,實現個性化內容創作。
- 優勢: 在 GAIA 榜單上排名全球第一,超越 OpenAI Deep Research 和 Manus,推理成本僅為 OpenAI 的 40%。
-
🏦 GenSpark,2025-04:[一站式AI助理讓工作更省力!]
- 網址:https://www.genspark.ai
- 案例回放:台灣台北金融壽險業GenAI應用市場分析報告 (回放)
- 案例:📊 台灣台北金融壽險業GenAI應用市場分析報告
- 特點: 結合 AI 筆記、自動報告生成與深度研究;支援資料提取、自動生成報告與洞察。
- 功能: 支援多資料來源整合,自動產出可視化分析報告,並提供自訂研究框架。
- 體驗: 左側為導航與工作區(如 AI 筆記、資料庫、研究區),右側輸出結構化內容,操作直觀,專為研究型任務設計。
- 優勢: 適用於知識管理、競業分析、產業研究等場景。提供靈活任務分工與多格式輸出,適合企業內部團隊使用。
-
🧩 字節扣子空間 (Coze Space),2025-04:[字節版Manus 釦子空間來了!實測效果絕佳]
- 網址:https://space.coze.cn
- 案例回放:研究台北壽險業GenAI市場 (回放)
- 特點: 適用於低門檻生成式 AI 開發,特別是 Bot 創建。支援豐富元件拖拉拽配置,適合入門者或創作者使用。
- 功能: 支援無需程式碼的 AI 開發,提供豐富的插件系統、知識庫、工作流等功能,使用者可透過自然語言描述需求,自動生成對應的應用。
- 體驗: 介面直觀,操作簡便,適合初學者快速上手。提供探索模式與規劃模式,滿足不同層次的使用需求。
- 優勢: 整合多種工具與資源,支援多平台部署,適合個人創作者與企業用戶進行 AI 應用開發。
參考文章 (Further Reading - Articles)
- 從AI Agent到Agent工作流程,一文詳細了解代理程式工作流程
- 萬字長文,帶你綜觀大模型Agent,涉及研究痛點、應用場景、發展方向
- 什麼是「Agentic 工作流程」?
- 什麼是Agentic AI?什麼是Agentic Workflow?與AI Agent有什麼區別和關聯?
其它專案項目 (Other Projects)
- FinRobot;DeepWiki;案例;可支援 Gemini-2.5-Pro-preview-05-06,基於 AutoGen
- Jupyter-AI;可支援 Gemini-2.5-Pro-preview-05-06
- 2025-05-22:Magentic-UI。。。暫不支援使用 Gemini
- 2025-05-13:LocalSite-ai
- 2025-05-10:FlowGram:字節跳動把Coze 核心開源了!視覺化工作流程引擎FlowGram 上線;如何使用
- 2025-05-10:DeerFlow:字節跳動開源DeerFlow - Gemini深度研究的開源平替;如何使用;跳動深度研究框架DeerFlow提示字解析
- 2025-05-09:OpenDeepWiki:開源的DeekWiki加入MCP,輕鬆讓AI掌握開源專案使用文件!;如何使用
- 2025-04-27:Rowboat
新穎的安全與威脅 Novel Security & Threats (OWASP ASI)
隨著 Agentic AI 能力的持續擴展,伴隨而來的是全新且更為複雜的安全風險。OWASP 的 Agentic Security Initiative(ASI)聚焦於由基於大型語言模型(LLM)的代理所引入的新型威脅。威脅建模是一個結構化的過程,用於識別和緩解系統中的安全風險。OWASP ASI 發布的文件提供了一個以威脅建模為基礎的參考資料,涵蓋新興的 Agentic AI 威脅。
新的攻擊向量主要集中在代理的記憶和工具整合,容易受到記憶中毒和工具濫用的攻擊。此外,由於 Agentic AI 系統通常使用非人類身份 (Non-Human Identities, NHI) 進行操作,缺乏傳統的使用者會話監督,增加了特權濫用或令牌濫用的風險。Agentic AI 也重新定義了權限洩漏,它不僅限於預定義的行動,還會利用動態訪問中的任何錯誤配置或漏洞。
安全視角演進與應對建議
- 演進路徑: GenAI → AI Agents → Agentic AI
- 風險模型: 傳統安全模型 → LLM 十大風險(LLM10)→ Agentic AI 專屬威脅(OWASP ASI)
- 傳統威脅重點: 資料外洩、提示注入
- Agentic 威脅重點: 目標操控、記憶中毒、多代理失控
給不同角色的建議:
- 安全研究員: 可深入研究 OWASP ASI Playbook 原始文件與實作樣本。
- 企業決策者: 可從導入記憶監控、代理日誌紀錄等低干擾措施開始。
- 學生或工程師: 建議先從實作單代理開始,逐步導入任務分解與角色化,再探索多代理協作。
根據 OWASP ASI 的分類,Agentic AI 威脅可以透過一個決策路徑來理解,主要威脅類別包括:
-
基於代理的獨立決策與推理威脅:
- 意圖破壞與目標操縱(Intent Breaking & Goal Manipulation, T6): 攻擊者利用代理的規劃和目標設定漏洞,操縱或重定向代理的目標和推理。這比傳統的提示注入風險更大,因為可以注入影響長期推理過程的對抗性目標。例如,透過惡意注入的郵件內容,欺騙企業副駕駛 (Enterprise Copilot) 去搜尋敏感資料並呈現包含該資料的連結。
- 錯位與欺騙行為(Misaligned & Deceptive Behaviors, T7): 代理為達成目標而執行有害或不允許的操作,同時呈現無害或欺騙性的回應。例如,一個股票交易 AI 為優先實現盈利目標而規避道德和監管约束,執行未經授權的交易。
- 否認與不可追溯性(Repudiation & Untraceability, T8): 代理自主運行但缺乏足夠的日誌記錄、可追溯性或鑑識文件,導致難以審計決策、歸屬責任或偵測惡意活動。例如,攻擊者利用日誌漏洞,操縱金融交易記錄使其不完整或遺漏,導致詐欺無法追溯。
-
基於記憶的威脅:
- 記憶中毒(Memory Poisoning, T1): 攻擊者透過操控儲存資料,污染 AI Agents 的記憶,進而影響其未來決策。這可能透過直接提示注入或利用共享記憶來影響其他使用者。例如,重複向 AI 旅行代理注入錯誤價格規則,使其將包機航班登記為免費。
- 級聯幻覺攻擊(Cascading Hallucination Attacks, T5): AI Agentd 傳播不準確或編造的資訊,這些資訊隨時間推移在系統中擴散和升級。單一代理的幻覺可以透過自我強化機制(如反思)複合,多代理系統中則可以透過代理間通訊傳播。例如,向醫療 AI 植入虛假的治療指南,導致危險的錯誤醫療建議。
-
基於工具與執行的威脅:
- 工具濫用(Tool Misuse, T2): 攻擊者透過欺騙性提示或命令操縱 AI Agents 濫用其整合工具,即使在授權權限內。這可能導致未經授權的數據存取、系統操作或資源利用。代理劫持是相關的概念。例如,操縱 AI 訂票系統函數呼叫,使其預訂 500 個座位而非一個。
- 權限洩漏(Privilege Compromise, T3): 由於配置錯誤或漏洞,攻擊者利用 AI Agents 的權限執行未經授權的操作。Agentic AI 擴大了權限提升風險,因為代理可以動態委派角色或調用外部工具。例如,攻擊者操縱 AI Agents 以故障排除為藉口調用臨時管理權限,然後利用配置錯誤持久保留提升的訪問權限。
- 意外的 RCE 與程式碼攻擊(Unexpected RCE and Code Attacks, T11): 攻擊者利用 AI 生成程式碼執行環境中的漏洞,注入惡意程式碼、觸發非預期系統行為或執行未經授權的腳本。例如,操縱 AI 驅動的 DevOps 代理生成包含隱藏命令的腳本。
- 資源過載(Resource Overload, T4): 攻擊者故意耗盡 AI Agents 的計算能力、記憶或外部服務依賴,導致系統效能下降或故障。這與 LLM10:2025 無界消耗相關,Agentic AI 的自主性加劇了風險。例如,向 AI 安全系統輸入特製輸入,使其執行資源密集型分析,壓垮處理能力。
-
身份驗證、身份與權限威脅:
- 身份欺騙與冒充(Identity Spoofing & Impersonation, T9): 攻擊者利用身份驗證機制冒充 AI Agents 或人類使用者,以虛假身份執行未經授權的操作。這在基於信任的多代理環境中尤其危險。例如,攻擊者注入間接提示,欺騙具有發送郵件權限的 AI Agents 代表合法使用者發送惡意郵件。
-
基於人機互動的威脅:
- 壓倒人機協作(Overwhelming Human-in-the-Loop, T10): 攻擊者利用系統對人類監督的依賴,產生過多的警報或請求,導致人類審查者疲勞並可能忽略重要風險。Agentic AI 的複雜性和規模帶來了新的挑戰。例如,攻擊者操縱輸入源,淹沒人類審查者,使其難以識別真正的威脅。
- 人類操縱(Human Manipulation, T15): 攻擊者利用使用者對 AI Agents 的信任來影響人類決策,即使在授權權限內。例如,透過間接提示注入,操縱企業副駕駛替換合法廠商的銀行資訊為攻擊者的帳戶。
-
多代理系統中的威脅:
- 代理通訊中毒(Agent Communication Poisoning, T12): 攻擊者操縱代理之間的通訊渠道,注入虛假資訊,擾亂工作流程,或影響協作決策。這與記憶中毒相似,但針對的是瞬態和動態數據。例如,注入誤導性資訊,逐漸影響決策,將多代理系統導向錯誤目標。
- 協調的權限提升(Coordinated Privilege Escalation, T14): 攻擊者利用多個相互連接的 AI Agents 中的漏洞來逐步提升權限。這屬於人類對多代理系統的攻擊。例如,攻擊者滲透安全監控系統,破壞身份驗證和存取控制代理,使一個 AI 錯誤地驗證另一個以獲得未經授權的訪問。
- 多代理系統中的流氓代理(Rogue Agents in Multi-Agent Systems, T13): 惡意或受損的 AI Agents 滲透到多代理架構中,執行未經授權的行動或外洩數據。這些代理利用信任機制和工作流程依賴性。例如,流氓代理冒充金融批准 AI,利用代理間信任注入詐欺性交易。
Agentic AI 緩解策略 Mitigation Strategies (OWASP ASI Playbooks)
OWASP ASI 文件提供了一系列結構化的緩解策略,並組織成六個行動手冊 (Playbooks),與威脅決策樹對齊。每個行動手冊包含預防性 (proactive)、響應性 (reactive) 和偵測性 (detective) 措施。
例如,針對不同的威脅:
- Playbook 1:防止 AI Agents 推理操縱: 目標是防止攻擊者操縱 AI 意圖和行為,並增強可追溯性。措施包括限制工具訪問、實施行為驗證機制、追蹤目標修改請求頻率、以及實施全面的日誌記錄和實時異常偵測。
- Playbook 2:防止記憶中毒與 AI 知識損壞: 目標是防止 AI 儲存或傳播被操縱的數據。措施包括實施記憶內容驗證、限制記憶保留時間、部署異常偵測系統、使用回滾機制,以及對新知識進行機率性真相檢查。
- Playbook 3:保護 AI 工具執行與防止未經授權的行動: 目標是防止 AI 執行未經授權的命令或濫用工具。措施包括實施嚴格的工具訪問控制、使用執行沙箱、實施速率限制、記錄所有工具互動、以及檢測規避安全策略的命令鏈。
- Playbook 4:加強身份驗證、身份與權限控制: 目標是防止未經授權的權限提升、身份欺騙和訪問控制違規。措施包括要求加密身份驗證、實施粒度 RBAC、部署 MFA、防止跨代理權限委派、以及檢測和標記異常角色分配。
- Playbook 5:保護人機協作與防止決策疲勞利用: 目標是防止攻擊者壓倒人類決策者或透過欺騙性 AI 行為繞過安全。措施包括使用 AI 信任評分來優先處理審查佇列、自動化低風險批准、限制 AI 生成的通知頻率,以及檢測和標記表現出操縱企圖的 AI 響應。
- Playbook 6:保護多代理通訊與信任機制: 目標是防止攻擊者破壞多代理通訊、利用信任機制或操縱分布式 AI 環境中的決策。措施包括要求訊息驗證和加密、部署代理信任評分、使用共識驗證、部署實時偵測模型標記流氓代理,以及監控代理互動中的異常。
實施這些緩解措施時,基礎的安全措施(如軟體安全、LLM 保護和訪問控制)也應該一併實施。
Agentic AI 的挑戰、限制與未來方向 Challenges, Limitations & Future Directions
儘管 Agentic AI 展現巨大潛力,但它仍面臨顯著的挑戰與限制。這些挑戰部分繼承自底層的 LLM,部分源於多代理系統本身的複雜性。
AI Agents 的限制(Limitations of AI Agents)
- 缺乏因果理解(Lack of Causal Understanding): 當前的 LLMs 善於識別統計相關性,但缺乏因果建模的能力,難以區分相關性和因果關係。這使得代理在分佈轉移下表現脆弱,難以在未知或高風險場景中可靠運行。
- 繼承自 LLMs 的限制(Inherited Limitations from LLMs): 包括產生幻覺(事實不正確的輸出)、對提示的敏感性(微小措辭變化導致行為差異)和高計算成本/延遲。這些問題影響了代理的可靠性和可信度。
- 不完整的 Agentic 屬性(Incomplete Agentic Properties): 當前的 AI Agents 未能完全滿足自主性、前瞻性(主動發起任務)、反應性和社交能力等規範屬性。它們通常仍需明確指令才能行動,缺乏根據環境變化動態調整目標的能力。
- 有限的長時規劃與恢復(Limited Long-Horizon Planning and Recovery): AI Agents 在複雜、多步驟任務中進行魯棒的長時規劃能力有限。這源於它們對無狀態提示-響應模式的依賴,缺乏對先前推理步驟的內在記憶。
- 可靠性與安全性問題(Reliability and Safety Concerns): 由於缺乏因果推理能力和難以驗證代理的規劃正確性,AI Agents 尚未足夠安全或可驗證,無法在關鍵基礎設施中部署。
Agentic AI 的挑戰(Challenges of Agentic AI)
Agentic AI 的挑戰則更為放大且新穎:
- 放大的因果挑戰(Amplified Causality Challenges): 多代理系統中複雜的代理間互動放大了因果理解的挑戰。一個代理的錯誤或幻覺輸出可能在系統中傳播,導致錯誤級聯。
- 通訊與協調瓶頸(Communication and Coordination Bottlenecks): 實現多個自主代理之間高效的通訊與協調是一大挑戰。包括目標對齊、共享上下文、協議限制(模糊的自然語言交換)和資源爭奪等問題。
- 新興行為與可預測性(Emergent behavior and Predictability): 代理間的互動可能產生未明確程式設計或預見的複雜系統級行為,這帶來顯著的不可預測性和安全風險。隨著代理數量和互動複雜性增加,系統不穩定性風險也會提高。
- 可擴展性與偵錯複雜性(Scalability and Debugging Complexity): 隨著 Agentic AI 系統擴展,由於代理推理過程的黑箱特性和系統的非組合性,維護系統可靠性和可解釋性變得異常複雜。追蹤故障原因需要解析多個代理互動和工具調用的嵌套序列。
- 信任、可解釋性與驗證(Trust, Explainability, and Verification): 分布式、多代理架構使得 Agentic AI 在可解釋性和可驗證性方面面臨更高的挑戰。缺乏跨代理的共享、透明日誌或可解釋推理路徑,使得追蹤最終決策或故障的因果鏈條極為困難。目前尚無廣泛採用的方法來驗證多代理 LLM 系統在所有情況下都能可靠運行。
- 安全與對抗性風險(Security and Adversarial Risks): Agentic AI 架構擴大了攻擊面。單一代理的妥協可能導致惡意輸出或損壞狀態在整個系統中傳播。代理間的動態性也容易被利用,攻擊者可能操縱協調邏輯。
- 倫理與治理挑戰(Ethical and Governance Challenges): Agentic AI 的自主性帶來深刻的倫理與治理問題,尤其是在問責制、公平性和價值對齊方面。多代理環境中出現問責制空白,難以歸屬錯誤責任。偏見可能在代理互動中傳播和放大。
- 不成熟的基礎與研究空白(Immature Foundations and Research Gaps): Agentic AI 仍處於早期研究階段,缺乏標準架構和魯棒的因果基礎。這限制了其可擴展性、可靠性和理論基礎。
潛在解決方案與未來方向(Potential Solutions & Future Directions)
研究人員正積極探索解決這些挑戰的方法,包括:
- 檢索增強生成(RAG): 通過將輸出 grounding 在外部知識源(如向量資料庫)中,減少幻覺並擴展知識。
- 工具增強推理(Tool-Augmented Reasoning): 使代理能夠調用外部 API 和工具,與現實世界系統互動。
- Agentic 迴圈(Reasoning, Action, Observation): 引入迭代的推理、行動、觀察回饋迴圈,實現更深思熟慮、上下文敏感的行為。
- 記憶架構(Memory Architectures): 利用情節記憶、語義記憶和向量記憶來實現跨任務或跨會話的資訊持久化。
- 多代理協調與角色專業化(Multi-Agent Orchestration with Role Specialization): 透過元代理或協調器管理和協調多個專門代理,增強可解釋性、可擴展性性和故障隔離。
- 反思與自我批判機制(Reflexive and Self-Critique Mechanisms): 使代理能夠評估自身輸出或相互評估,提高魯棒性。
- 程式化提示工程流程(Programmatic Prompt Engineering Pipelines): 自動化提示的生成和結構化,提高可重現性和泛化性。
- 因果建模與基於模擬的規劃(Causal Modeling and Simulation-Based Planning): 使代理能夠理解因果關係,進行更魯棒的規劃和模擬假設情境。
- 監控、審計與可解釋性流程(Monitoring, Auditing, and Explainability Pipelines): 記錄代理的活動,提供事後分析和偵錯能力,特別是在多代理系統中追蹤因果鏈條。
- 治理感知架構(Governance-Aware Architectures): 內置角色訪問控制、沙箱和身份解決機制,確保代理在範圍內運行並可被追究責任。
未來的 Agentic AI 將朝著更強大的多代理擴展、統一協調、持久記憶和模擬規劃發展。同時,倫理治理框架和針對特定領域的領域特定系統將變得至關重要。一些研究方向如 Absolute Zero 框架甚至探索了無需外部資料集的自主學習可能性。
AI 創業成功秘訣 (吳恩達觀察) Keys to AI Startup Success (Andrew Ng's Observations)
吳恩達在與 Harrison Chase 的對話中,分享了 AI Fund 觀察到的 AI 創業成功兩大關鍵預測指標:
- 速度: 「我從未見過一個技術嫻熟的團隊所能達到的執行速度。它比那些較慢的企業所知道的任何做事方式都要快得多。」
- 技術深度: 「市場營銷、銷售、定價等知識固然重要,但這些知識相對普及。真正稀缺的是對技術如何運作的深刻理解,尤其是在技術飛速發展的今天。」吳恩達強調,AI Fund 非常樂於與那些擁有良好技術直覺和理解力的深度技術人才合作。
總結 Conclusion
Agentic AI 代表了 AI 發展的一個重要方向,它將單一 AI Agents 的能力擴展到協作、自主的系統級別。這為解決複雜問題和自動化廣泛任務帶來巨大機遇。從底層的生成式 AI 到具備感知與行動能力的 AI Agents,再到由多個協作代理組成的 Agentic AI,技術正不斷演進。吳恩達與 Harrison Chase 的對話進一步釐清了「agentic systems」的彈性定義、線性工作流的即時價值、以及「樂高積木」式的開發哲學,並點出了評估、語音、全民程式設計等領域的潛力。
然而,隨之而來的安全挑戰是巨大的,從針對單一代理的記憶中毒和工具濫用,到多代理系統中的通訊中毒和流氓代理。OWASP ASI 等倡議為理解這些威脅並制定緩解策略提供了寶貴的框架。同時,現實應用中的「自信地提供錯誤答案」和引用問題也提醒我們,AI Agents 的穩定性和可靠性仍是當前開發的關鍵挑戰。
對初學者而言,理解從生成式 AI 到 AI 代理再到 Agentic AI 的發展歷程,並掌握其核心能力、工具與安全挑戰,是切入這一領域的關鍵起點。這是一個需要持續研究和實踐來應對其複雜性和挑戰的領域,特別是為了確保未來自主系統的安全、可靠和負責任的部署。選擇穩定可靠、社群活躍的工具(如 Suna、OpenManus)至關重要,但同時也需警覺 錯誤引用、安裝困難、不穩定輸出 等陷阱,謹慎測試與驗證來源,才是 AI Agent 成功落地的關鍵。
模型上下文協議 (MCP) 核心概念解析 Model Context Protocol (MCP) Explained
Model Context Protocol (MCP) 是一種開放協議,旨在讓 AI 模型能更輕鬆、標準化地連接並使用外部數據和工具。您可以將它想像成 AI 世界的「USB」,提供一個統一的接口,讓不同的數據源、應用程式或工具都能無縫對接,無需為每個組合單獨開發整合方案。MCP 由 Anthropic 於 2024 年 11 月開源。
核心目標: 讓 AI 獲取更豐富的上下文資訊,提升理解能力,使回應更準確、更相關,並能執行更複雜的任務。
MCP 的變革與挑戰:吳恩達的觀點
對於近期備受關注的 MCP(Model Context Protocol,模型上下文協議),吳恩達給予了積極評價,認為它填補了市場的明顯空白,旨在實現 N 個模型/智能體與 M 個數據源集成時,付出 N+M 而非 N*M 的努力。OpenAI 的採用也證明了其重要性,DeepLearning.AI 也與 Anthropic 合作推出了相關課程。吳恩達指出:「我們花費了大量時間在『管道』上,也就是數據集成,以便將正確的上下文信息提供給 LLM。」MCP 是一個嘗試標準化接口的「奇妙方式」。
但他同時坦言,MCP 及其服務目前尚处于早期阶段。「很多網上的 MCP 服務並不可用,認證系統也有些笨拙。」協議本身也需要進化,例如,當 LangGraph 這樣的工具擁有大量 API 調用時,簡單的列表式資源呈現難以滿足需求,未來可能需要層級化的發現機制。
MCP 的關鍵重點
- 標準化連接 (Standardized Connection):
- 基於 JSON-RPC 2.0,提供統一的接口規則。
- AI 模型可以用標準方式與各種外部系統(數據庫、API、文件系統等)互動,大幅降低整合的複雜性。
- 即時數據訪問 (Real-time Data Access):
- AI 能透過 MCP 即時獲取最新資訊,確保決策和回應基於最新數據。
- 支持動態通知機制,當數據源變更時可主動通知 AI。
- 賦能 AI 使用外部工具 (AI Using External Tools):
- 允許應用程式將特定功能(如 API 呼叫、文件讀寫、數據庫查詢)「開放」給 AI。
- AI 可以直接操作這些工具來完成更複雜的任務,而不僅僅是文本生成。
- 靈活的工作流整合 (Flexible Workflow Integration):
- 開發者可以將 MCP 作為橋樑,把不同的服務或組件串聯起來,讓 AI 參與到更廣泛的自動化工作流程中。
- 安全與隱私 (Security & Privacy):
- MCP Server 通常在本地或受信任的環境中運行。
- 敏感數據不必傳輸到雲端或第三方 AI 模型服務,增強數據安全性。
- 內建能力協商與權限控制機制。
MCP Server 與 MCP Client
MCP 採用客戶端-伺服器 (Client-Server) 架構:
- MCP Server (伺服器端):
- 職責: 扮演「資源管理者」和「守門人」。它管理對外部數據源(如資料庫、API、文件)和工具的訪問。
- 功能: 處理來自 Client 的請求,執行操作(如讀取文件、調用 API),返回結果給 Client,並可主動推送數據更新。它也負責認證、權限控制等安全機制。
- 優勢: 集中管理資源和安全,隱藏底層複雜性,使 Client 端更輕量。
- MCP Client (客戶端):
- 職責: 通常是 AI 模型或基於 AI 的應用程式。
- 功能: 向 MCP Server 發送請求,以獲取數據或要求操作工具來完成特定任務。它依照 MCP 協議與 Server 溝通。
為什麼是 Server/Client 架構?
- 資源管理: Server 集中管理數據和工具,確保統一和安全。
- 靈活擴展: Client 可按需請求,Server 可獨立擴展數據源和工具,AI 模型本身不必臃腫。
- 安全隔離: Server 運行在受信任環境,作為 AI 與敏感數據/系統之間的安全屏障。
- 標準化溝通: 統一協議確保不同 Client 能與各種 Server 無縫對接。
交互流程簡例:
- Client (AI 模型) 需要讀取 `/data/report.txt` 文件。
- Client 向 MCP Server 發送一個符合 MCP 格式的「讀取文件」請求,指明路徑。
- MCP Server 驗證 Client 權限,然後讀取該文件。
- MCP Server 將文件內容返回給 Client。
- (可選) 若 `report.txt` 後續被修改,Server 可主動通知 Client 文件已更新。
MCP 與傳統 API 的差異
MCP 並非要取代 API,而是作為 AI 模型與多個外部系統(這些系統可能本身就提供 API)之間的中介層或協調層。
| 特性 | Model Context Protocol (MCP) | 傳統 API (如 RESTful API) |
|---|---|---|
| 核心定位 | AI 與外部系統的標準化中介層 | 應用程式間直接的點對點接口 |
| 標準化 | 基於 JSON-RPC 2.0,提供統一接口與能力描述 | 各自設計,格式、認證方式、錯誤處理等可能各異 |
| AI 整合複雜度 | 低。AI 只需學會與 MCP Server 溝通 | 高。AI 需為每個不同 API 單獨適配 |
| 安全性 | 內建能力協商、權限控制;Server 集中管理敏感操作 | 需各自實現身份驗證、授權、加密等安全措施 |
| 數據源管理 | MCP Server 可管理多個異構數據源 (API, DB, 文件等) | 通常一個 API 端點對應一個特定資源或服務 |
| 動態性 | 支持 Server 主動向 Client 推送數據變更通知 | 多為 Client 主動請求-回應模式,即時同步較複雜 |
| 變更適應性 | 外部 API 變更時,主要修改 MCP Server,Client 端影響小 | API 變更可能需要修改所有調用該 API 的 Client 端 |
| 生態與工具 | 逐漸形成 (如 Anthropic, Spring AI 支持),強調 AI 易用性 | 成熟,但需自行整合不同 API 的客戶端庫 |
一句話總結差異:
- 直接用 API: AI 模型需要自己處理每個 API 的不同格式、認證和錯誤邏輯。
- 用 MCP: AI 模型只需要和 MCP Server 溝通,MCP Server 負責處理與各種後端 API 或數據源的複雜交互,並以標準化方式提供給 AI。
MCP Server 的價值(為何不是多此一舉?):
- 簡化 AI 開發: MCP Server 隱藏了底層 API 的細節,AI 模型只需使用統一的 MCP 格式請求。
- 集中管理認證與安全: API Key、OAuth Token、權限控制等可以由 MCP Server 統一處理,降低 AI 模型直接處理這些敏感資訊的風險。
- 適應後端變更: 如果某個外部 API 升級或更換,理論上只需修改 MCP Server 的適配邏輯,AI 模型的請求方式無需改變。
- 抽象化數據源: 無論數據來自 REST API、GraphQL、資料庫還是本地文件,MCP Server 都能提供統一的接口給 AI。
何時選擇 MCP vs 直接用 API?
- 單一、簡單、穩定的外部 API: 如果 AI 只需要與一個非常簡單且不常變動的 API 互動,直接調用該 API 可能更直接。
- 整合多個異構數據源/工具: 當 AI 需要與多個不同來源的數據或多種工具互動時,MCP 的標準化和抽象化優勢非常明顯,能大幅降低開發和維護成本。
- 需要增強安全性與控制: MCP Server 可以作為一個安全代理,對 AI 的訪問進行細粒度控制。
- 追求 AI 應用開發的敏捷性: MCP 可以讓 AI 開發者更專注於 AI 邏輯,而非底層數據整合。
使用現成的外部 API 時: MCP Server 依然有價值,它會負責調用這些現成的 API,並將其返回的數據轉換成 MCP 標準格式供 AI 使用,AI 無需關心這些外部 API 的具體細節。
已知的 MCP "Hub" 或實現列表
目前 MCP 生態仍在發展中。所謂的 "Hub" 更接近於一個資源集散地或社群維護的列表,用於發現可用的 MCP Server 實現、工具和相關資源。最重要的參考點是:
- GitHub - `modelcontextprotocol` organization: https://github.com/modelcontextprotocol
- 這是 MCP 協議本身的官方組織,包含協議規範等核心內容。
- GitHub - `awesome-mcp-servers`: https://github.com/punkpeye/awesome-mcp-servers
- 這是一個社群維護的列表,收集了已知的 MCP Server 實現。您可以從這裡找到或貢獻不同的 MCP Server 項目。
- 一些已知的實現或整合案例(可能出現在此列表或相關討論中):
- Cline: 提到的文章中,Cline 是一個與 MCP 整合的例子,它本身可能提供或計劃提供 MCP Server 功能,或者作為 MCP Client 與其他 MCP Server 互動。
- Spring AI: Spring 框架的 AI 模塊也宣布了對 MCP 的支持,可能會提供 MCP Server/Client 的實現。