Deep Learning 101, Taiwan’s pioneering and highest deep learning meetup, launched on 2016/11/11 @ 83F, Taipei 101

衷心感謝當時來自不同單位的AI同好參與者實名分享的寶貴經驗;如欲移除資訊還請告知。
由 TonTon Huang Ph.D. 發起,特別感謝時任職公司台灣雪豹科技無償贊助場地及茶水點心。
這裡不僅匯集了我們歷年的 Meetup 紀錄,更是 AI 演算法與開源資源匯整中心。
作者:TonTon Huang Ph.D.
Blog:2026年03月27日
相關文章:Sovereign Heuristic Intelligence & Enterprise Logic Defense (主權啟發式情資與企業邏輯防禦系統)
🎵 不聽可惜的 NotebookLM Podcast @ Google 🎵
從通用工具轉向「主權 AI 資產化工廠」
面對當前 AI 導入的困境,企業級 AI 的戰略必須從「採購通用 SaaS 工具」升級為「打造專屬主權 AI 資產」。如同法務部等高度敏感公部門的建置策略,企業應採用「底層資源共享、應用服務分流」的封閉式地端架構。這不僅能確保機密數據不出境,更能將每一次的模型微調與提示工程,轉化為企業專屬、可稽核的「數位員工」,徹底解決通用模型「不懂行業內規」的痛點。
企業級 AI 標竿分析與負責任 AI 治理建議
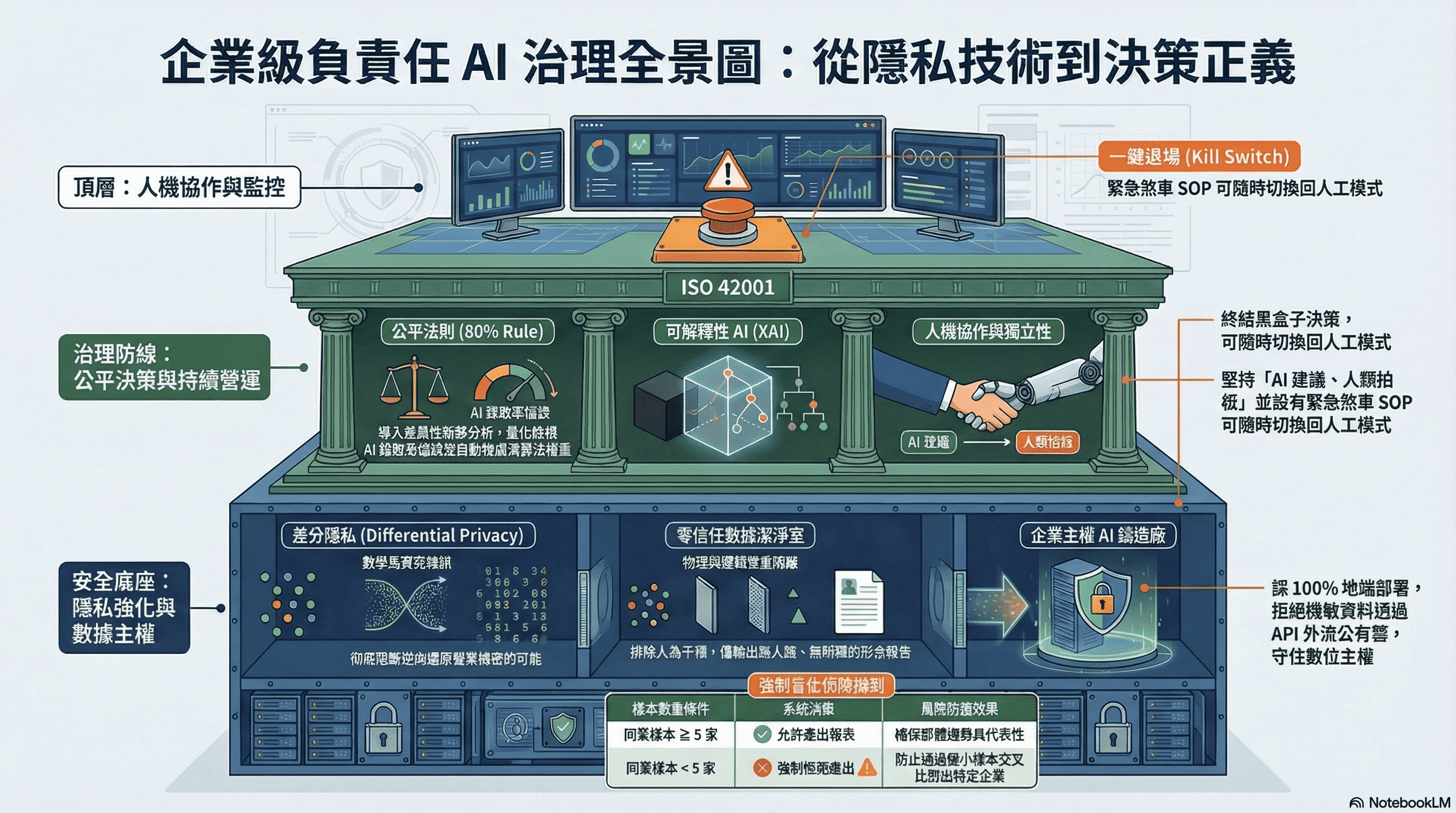
🧠 企業級可信賴 AI 治理 (認知與語意的貼身保鑣: 阻擋「AI 提示詞攻擊與系統幻覺」,不讓 AI 大腦被騙或做錯決定。)
👉 核心目標:保護 AI 大腦的神經智力,確保不被騙、不亂講話、絕對合規。
- 透明性 (Transparency):「讓黑箱變成玻璃箱」;系統有沒有偷偷做事?使用者問了 A,系統背後到底拿了哪些資料去組裝 Prompt?把每一次對話的輸入、檢索到的文件 (Context)、耗時、Token 消耗,全部記錄 (Tracing)。
- 可解釋性 (Explainability):「給出決策的理由」;當使用者問「你憑什麼給出這個答案」時,系統能給出證據。當 AI 說「這份標案不合規」時,必須標示出「AI 是基於資料庫裡的文檔 X 做出的回答,而不是自己幻想的。」
- 公平性 (Fairness):「一視同仁,沒有偏見」;不能因為申請人的性別、年齡或企業規模,而在沒有法規依據的情況下給出較差的評分。透過統計學與紅隊測試,掃描模型在不同群體上的「通過率」是否有異常落差。
- 人類自主 (Human in the loop):「關鍵決策,必須由人類批准」;寫好對外報價單或法律裁定草案,但寄出或生效前,必須由人類點擊「Approve」。工作流中設定「中斷點 (Breakpoints)」,跑到一半會暫停,等待人類確認後才繼續。
- 問責機制 (Accountability):「出事了,找誰算帳?」;證明系統出錯不是因為設計不良,而是模型極限,且我們有完整的稽核軌跡。把「在什麼時間、用什麼權限、觸發哪個 AI 節點、被誰審核通過」打包成不可篡改的日誌。
壹、標竿分析的矛盾:「知己知彼,卻不露底牌」

一、資訊共享的囚徒困境
企業想知道自己在市場上的真實競爭力,需要透過同業標竿分析 (Benchmarking) 來評估自身的營運效率與風險管理落點,這點無庸置疑。然而,傳統調查始終跨不過一道企業的防備心門檻:為了防範競爭對手,沒有企業願意把真實的營業數據、風險漏洞或核心演算法攤在陽光下,導致提供競爭對手致命把柄。這種「想看別人,卻不願被看」的心態,直接導致市場上充斥著經過層層美化的表面數字,而缺乏真實參考價值及具備公信力的基準數據。
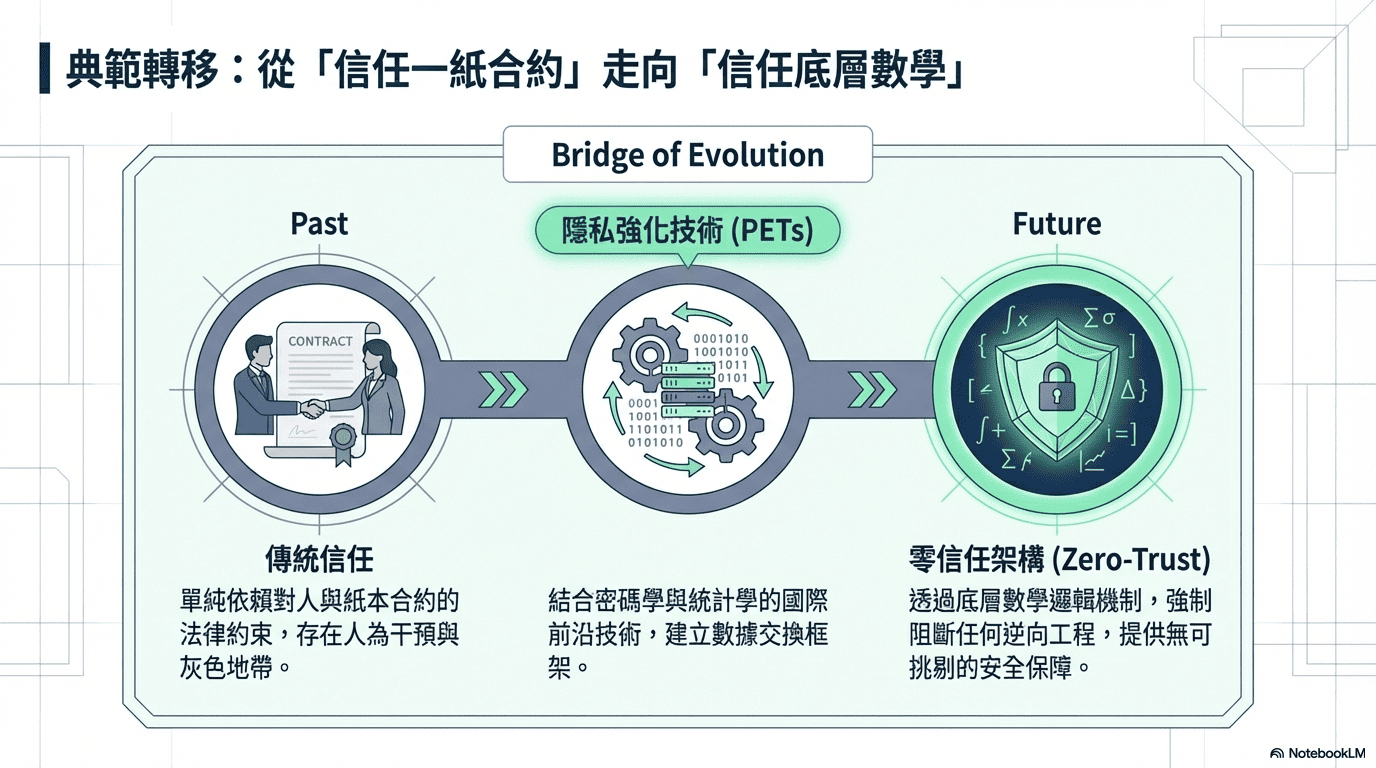
二、解決方案:從「信任人」轉向「信任數學」
為了突破這個資訊孤島的矛盾與僵局,不能僅單純依賴傳統對「人」與「紙本合約」的保密協定 (NDA) 的表面的法律約束;而是透過密碼學與統計學的結合,改採國際前沿的隱私強化技術 (PETs),建構 「零信任 (Zero-Trust)」 的數據交換框架;此框架不僅確保順利萃取出具備指標性的產業洞察,更重要的是,藉由數學底層邏輯機制,確保徹底阻斷被惡意逆向還原任何營業機密的可能;提供無可挑剔的安全保障。
貳、零信任標竿分析實作機制:差分隱私技術
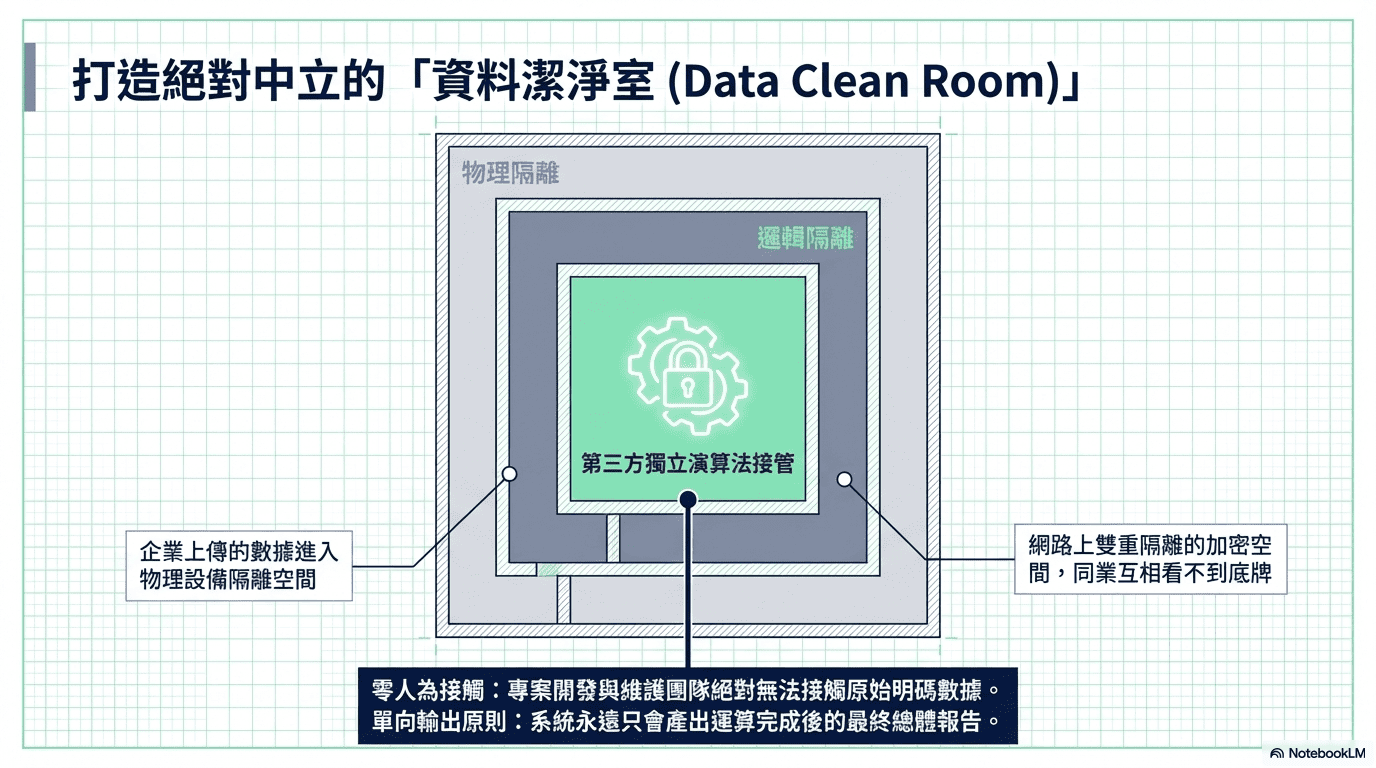
一、打造絕對中立的「隱私增強計算環境」
要讓所有企業放心交出核心數據,第一步就是建立一個沒有任何人能動手腳的空間。因此,企業上傳的數據,會進入一個在物理設備與邏輯網路上雙重隔離的加密環境。最核心的保障在於:徹底排除了「人」的干預,數據完全由第三方獨立演算法接管。沒有任何灰色地帶與後門,不僅同業互相看不到彼此的底牌,就連負責開發與維護的專案團隊,也絕對無法接觸到任何一筆原始的明碼數據;永遠只有運算完成後的最終總體報告。
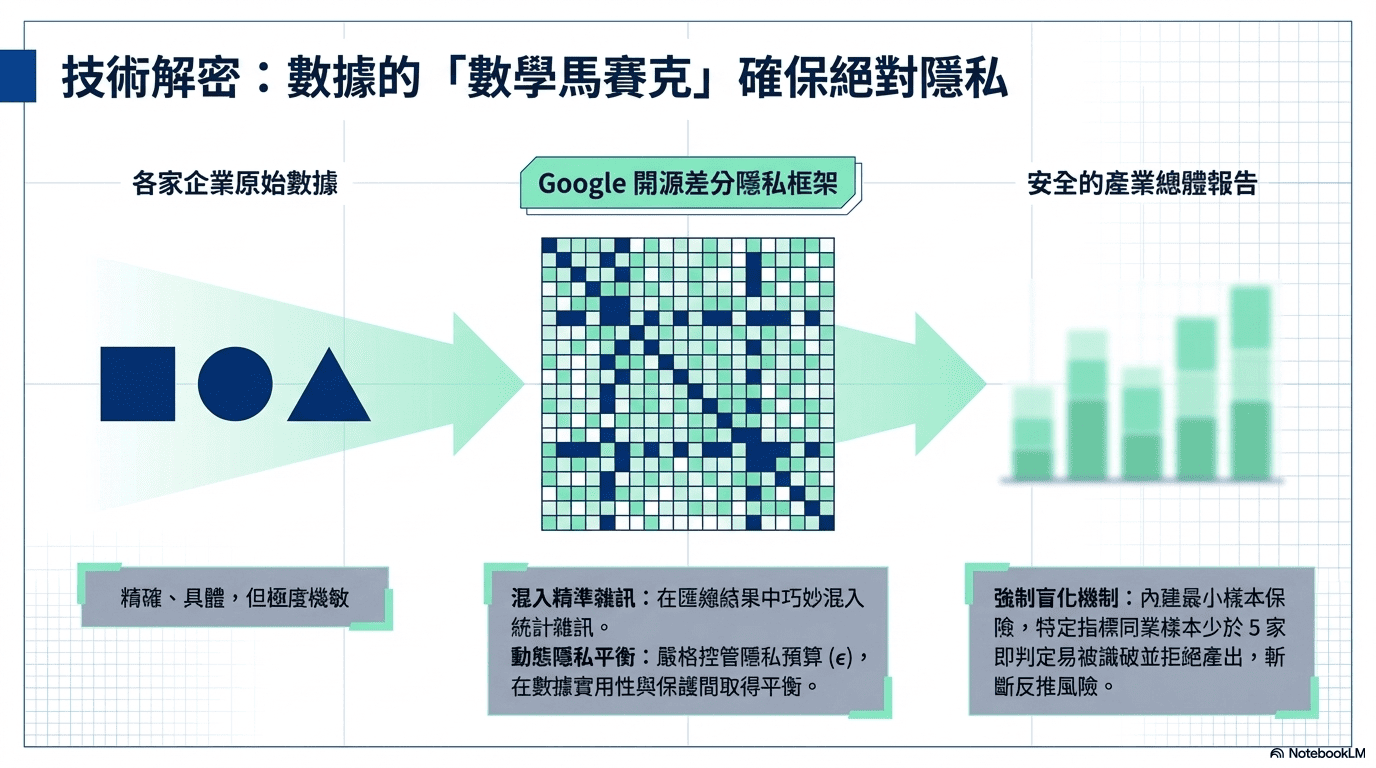
二、導入差分隱私技術 (Differential Privacy)
除了隔離,為了讓防禦落地,避免有心人士拿著公開報表,透過各種維度的「交叉比對」去反推某家公司的真實數據;將導入 Google 開源的 差分隱私框架。這項技術的原理,就像是在精密的數據上打上一層「數學馬賽克」;系統會在最終的匯總結果裡,巧妙地混入校準及經過精密的 「統計雜訊 (Statistical Noise)」;透過嚴格控管 隱私預算 ($\epsilon$),確保在「數據實用性」與「隱私保護」之間產出完美平衡的報表,既能精準反映產業的真實趨勢,又能讓有心人士無法藉由交叉比對,逆向挖出特定公司的數據。此外,系統還有一道 「強制盲化」 的保險:只要某項指標的同業樣本少於 5 家,系統就會判定「群體過小、容易被識破」,直接拒絕產出結果,從根本斬斷任何被反推的風險。
參、落地實踐:高風險 HR 領域的 AI 導入與比較
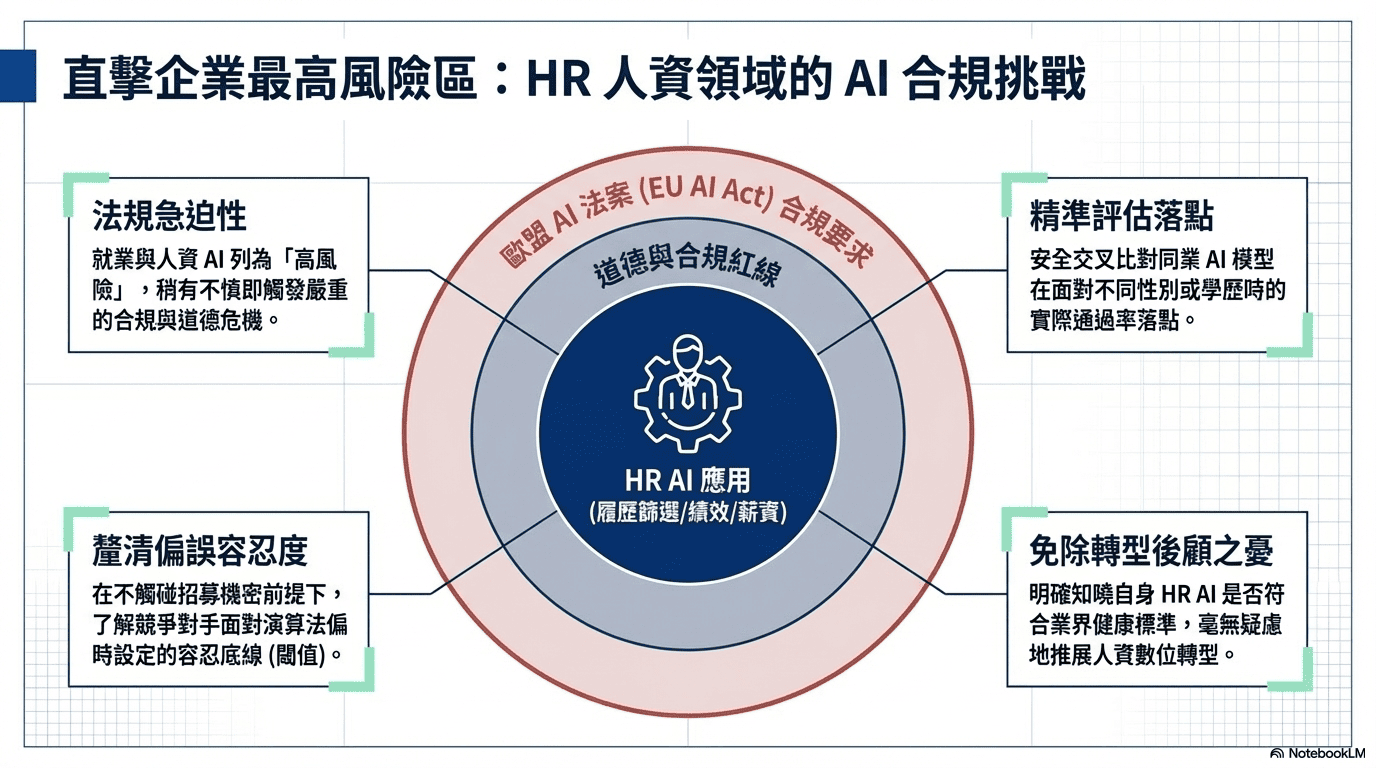
在確立了「安全且匿名」的標竿分析基礎設施後,將此機制率先應用於企業高度關注的人力資源 (HR) 領域。因為,隨著 AI 未來將有機會逐漸開始深度介入接管履歷篩選、績效評估甚至薪資建議,HR 已成為企業內部應用 AI 的「最高風險區」。歐盟 AI 法案 (EU AI Act) 更是已明確將就業與人資相關的 AI 系統列為 「高風險」。企業稍有不慎,踩到的不僅是道德紅線,更是嚴重的合規危機。
為了協助企業精準控管風險,透過前述的差分隱私機制,在完全不觸碰各家企業招募機密的前提下,安全地收集並交叉比對各家企業的 HR AI 表現,協助企業釐清:
- 同業的 AI 篩選模型,在面對不同性別或學歷時,實際的通過率落點在哪?是否存在潛在的歧視盲區?
- 當競爭對手面臨不可避免的「演算法偏誤」時,他們內部設定的容忍底線 (閾值) 究竟是多少?
透過這些匿名的加密盲化基準對齊數據,企業不再需要閉門造車,且將能明確知道自己的 HR AI 是否符合業界的「健康標準」,從頭到尾,毫無後顧之憂地推展人資數位轉型,徹底免除招募機密外洩的疑慮。
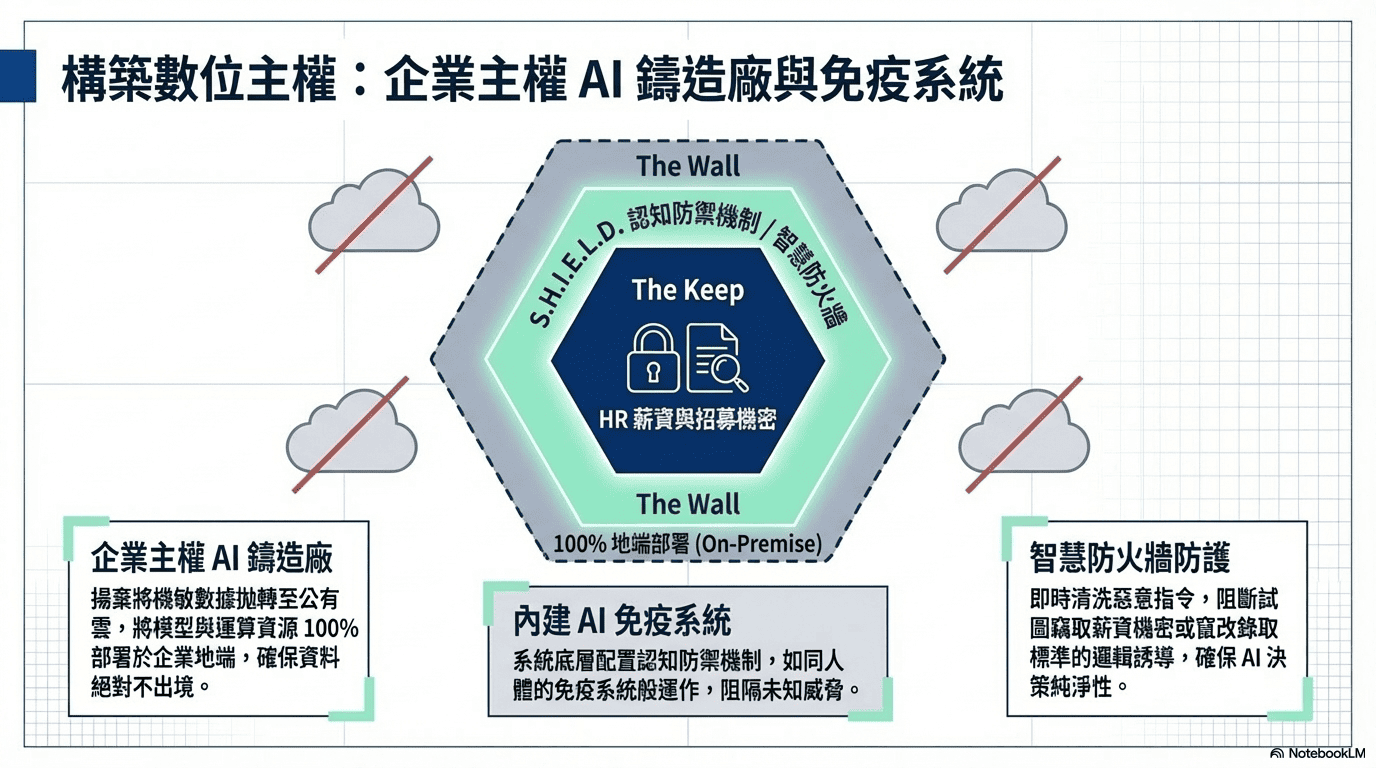
然而,要讓上述高機敏的 HR AI 應用真正安全落地,企業必須在底層架構確立絕對的 「數位主權」。建議揚棄將機敏招募與薪資數據透過 API 拋轉至公有雲的作法,改採 「企業主權 AI 鑄造廠」 概念,將模型與運算資源 100% 部署於企業地端,確保 資料不出境 的最高合規性。系統底層將內建如同 AI 免疫系統的認知防禦機制,能即時清洗惡意指令、阻斷試圖竊取薪資機密或竄改錄取標準的邏輯誘導,確保 AI 決策的純淨性,為人資數位轉型構築最堅實的安全底座。
肆、負責任的 AI:公平、透明與獨立的治理框架
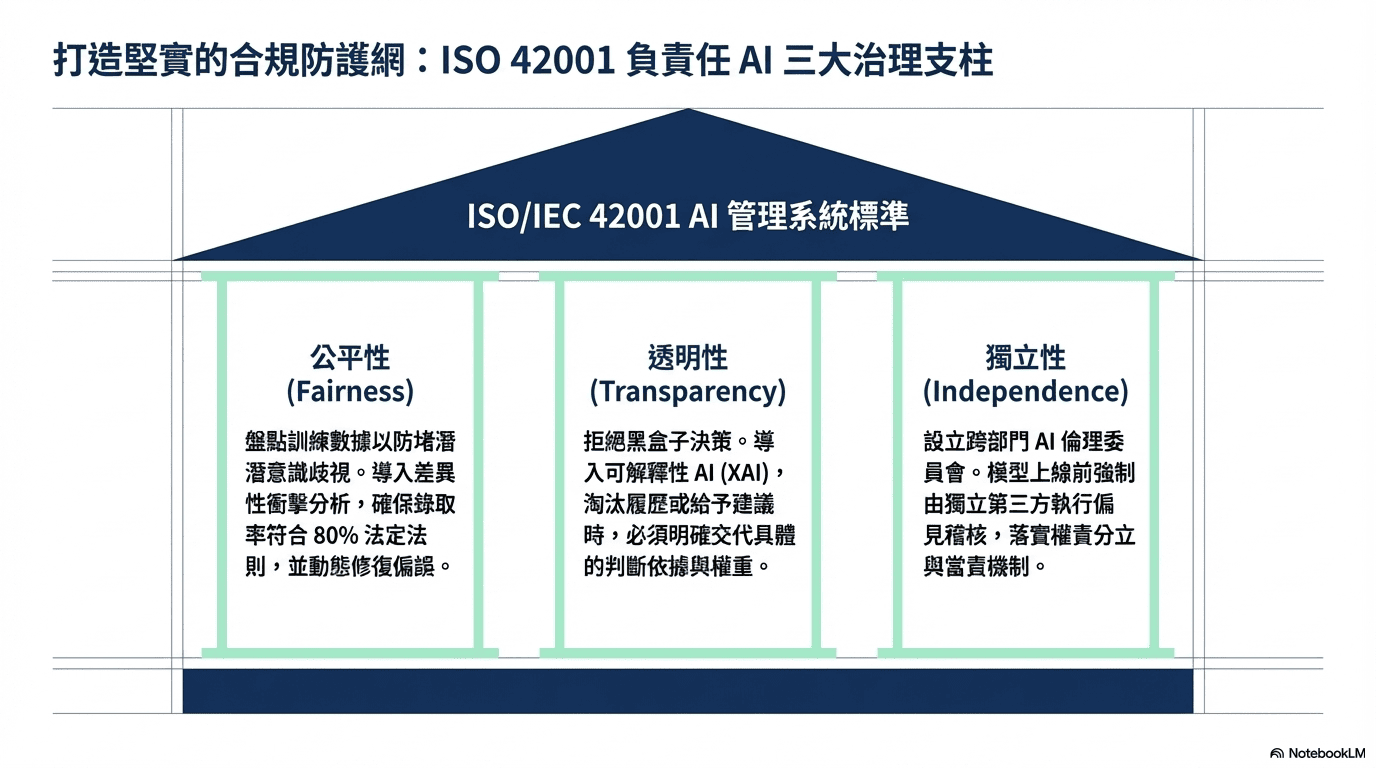
為了確保系統完全符合 ISO/IEC 42001 (AI 管理系統標準) 等國際規範,將從三大維度打造堅實的合規防護:全景觀測與可信賴 AI 治理 (Trustworthy AI Governance)
一、公平性與偏誤量化
目前主流的大型語言模型 (LLM) 其實藏著一個致命的盲區:它們是靠著無差別吸收海量歷史數據餵養長大的,這意味著,模型在訓練過程中,極容易把人類職場上長久以來根深蒂固的『潛意識歧視』直接複製貼上,變成它未來的決策邏輯。例如,模型可能會偷偷把「兵役狀況」當作篩選性別的代理變數。為了防堵這點,必須系統性地盤點訓練數據,並導入「差異性衝擊分析 (Disparate Impact)」等科學化數學模型。透過這類量化指標,我們能嚴格檢視 AI 對不同族群的錄取率是否達到法定的業界常參考的 80% 法則比例。一旦偵測到偏誤,系統將主動透過演算法權重調整來進行修復,從根本確保選才的公平性。
二、透明性與可解釋性
為了解決在 HR 領域,不能接受「因為 AI 說不行,所以不行」這種黑盒子決策的痛點,需導入 可解釋性 AI (XAI) 技術。這意味著,未來當 AI 決定淘汰某份履歷、或是給出特定的績效建議時,它都必須交代出具體的「判斷依據與權重」。這不僅能建立完善的知情同意流程,更能確保企業在面對求職者或監管機構的質疑時,隨時都能拿出清晰、透明的決策軌跡。
三、獨立性與當責機制
一套安全的系統,不能既當球員又當裁判。因此,在制度面上,強烈建議並將協助企業設立跨部門的 「AI 倫理委員會」 (涵蓋 HR、法務、資安與外部專家)。同時,在技術流程中設下硬性規定:任何 AI 模型在正式上線前,都必須交由未參與開發的獨立第三方團隊進行深度的 「偏見稽核」。透過這種權責分立的當責機制,確保系統上線後的每一天,都在企業的絕對掌控之中。
伍、永續營運與持續監控:防止模型崩壞的最後防線
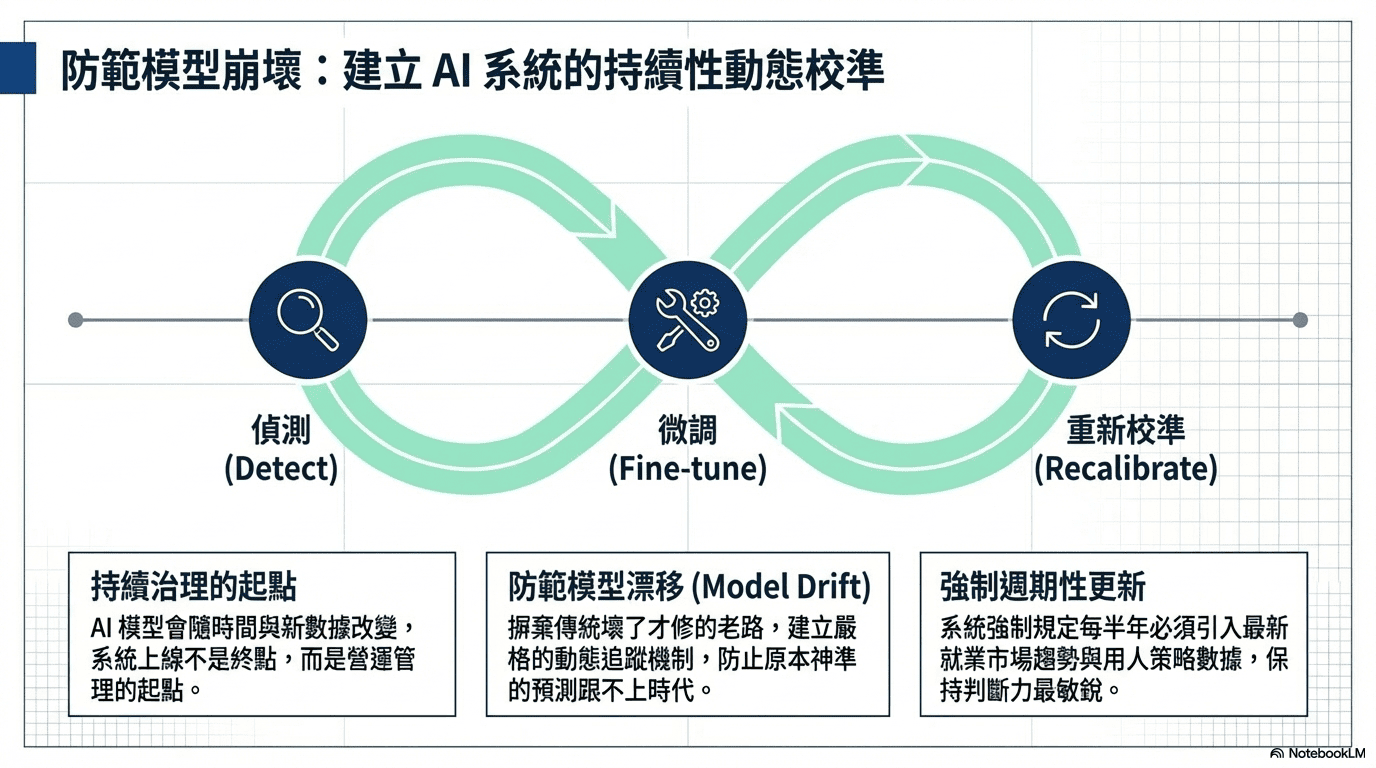
AI 模型跟傳統軟體最根本的不同在於:它會隨著時間與新數據不斷改變。因此,把系統順利推上線絕對不是專案的終點,而是「持續治理」的起點。為了確保這套系統能長治久安,需建立一套滴水不漏的營運機制:
一、防範模型漂移
就業市場的趨勢和企業的用人策略隨時都在變。如果放任不管,原本神準的 AI 預測,久了也會慢慢「跟不上時代」,這在技術上稱為模型漂移 (Model Drift)。為了解決這個問題,我們不走傳統軟體「壞了才修」的老路,而是建立嚴格的動態追蹤機制。系統會定期檢視 AI 的預測準確率,並強制規定每半年必須引入最新數據,為模型進行微調與重新校準,確保它的判斷力隨時保持在最敏銳、最貼近現況的狀態。
邁向零幻覺與全方位防禦:S.H.I.E.L.D. 雙層護欄
AI 治理的最後一哩路是抵禦惡意攻擊與技術先天缺陷。企業應導入類似 S.H.I.E.L.D. 的「內外雙層防禦」架構:
- 外層防禦 (Outer Defense): 建立 24/7 監控機制,主動偵測明暗網威脅,並在系統漏洞被利用前自動生成阻斷規則,有效縮短 0-day 攻擊的空窗期。
- 內層防禦 (Inner Defense): 設置專屬的邏輯防火牆,防範「提示詞注入 (Prompt Injection)」,確保模型不會因為使用者的惡意誘導而洩漏機密。
- 無向量檢索 (Vectorless RAG): 針對 RAG 架構中常見的幻覺問題,放棄模糊的向量空間,改以更精確的邏輯鎖定範圍,實現低成本且零幻覺的精準回應,確保 AI 給出的每一項建議都能 100% 回溯至真實條文。
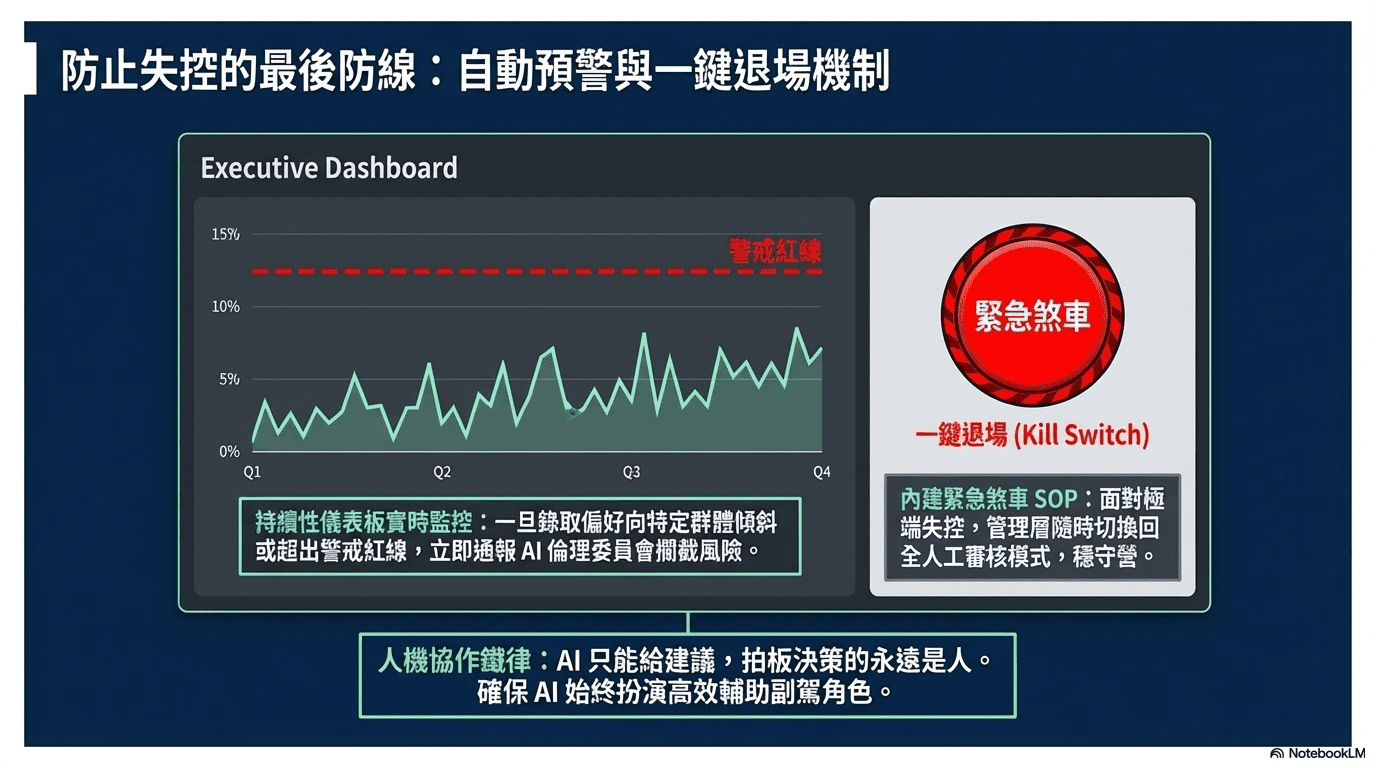
二、持續性儀表板與自動化預警
在系統後台建置一個直觀的監控面板,實時緊盯 AI 的決策有沒有「走鐘」。只要系統偵測到 AI 的錄取偏好開始向特定群體傾斜,或是超出了我們設定的警戒紅線,就會立刻觸發警報,並第一時間通報 AI 倫理委員會介入處理,把潛在的歧視風險攔截在災難發生之前。
建立可量測的「黃金範本 (Golden Sample)」與去識別化精煉
在 HR 或法規等高風險領域,要確保模型不帶偏見且合乎倫理,必須先建立一套作為「期末考卷」的黃金範本。實務上,企業應導入自動化去識別化工具(如 Microsoft Presidio),將原始履歷或機密卷宗內的個人敏感資訊(PII)徹底遮蔽或替換。這套經過「資料精煉」的黃金範本,將能作為後續評量 LLM 輸出公平性、正確性(例如要求正確率 ≥ 70%)與幻覺率(要求 < 20%)的絕對依據,讓 AI 治理具備真正的「可量測性」。
三、人機協作與接管機制
在 HR 這種牽涉個人職涯的高風險領域,必須踩死一條鐵律:「AI 只能給建議,拍板決策的永遠是人」。AI 在這裡的角色是高效的輔助副駕,絕非取代 HR。為了應對最極端的演算法失控狀況,系統內建了標準的緊急煞車 SOP。只要情況不對,管理層隨時能啟動 「一鍵退場」 功能,瞬間切換回全人工審核模式,確保企業營運與法規遵循享有絕對的安全底線。